Mašinsko učenje
Cilj BioSensove Grupe za veštačku inteligenciju je da obezbedi sveobuhvatan i precizan uvid u stanje biosistema, poveća efikasnost fenotipizacije i oplemenjivanja biljaka, ponudi bolje razumevanje molekularne biologije i pomogne poljoprivrednicima kroz optimalno i automatsko donešenje odluka. Naše istraživanje počinje od problema i zahteva inovativnu primenu i razvoj algoritama koji su poslednja reč nauke. Algoritmi mašinskog učenja koji se najčešće koriste za probleme kojima se BioSens bavi su stabla odluke, vektori nosači, ridž regresija, spektralno klasterovanje i mnogi drugi, uključujući i posebnu porodicu algoritama mašinskog učenja – duboko učenje, a tamo gde složenost problema prevazilazi postojeće algoritme, istraživači sa Instituta razvijaju nove.
Primer algoritma koji je razvijen na BioSens Institutu je algoritam regresije težinskim histogramima. Dati algoritam je zasnovan na mehanizmu glasanja, gde uzorci za obuku glasaju za izlaznu vrednost test uzorka. Svaki glas dobija određenu težinu u zavisnosti od sličnosti uzorka koji glasa i uzorka iz test skupa. Pomoću dobijenih glasova, formira se histogram koji de fakto predstavlja funkciju gustine verovatnoće (PDF) izlaza test uzorka, dok matematičko očekivanje PDF-a predstavlja predikovanu vrednost datog uzorka. Ovaj algoritam se pokazao veoma korisnim za problem predikcije prinosa, gde je nadmašio algoritme stabla odluke, vektora nosača i veštačkih neuronskih mreža.
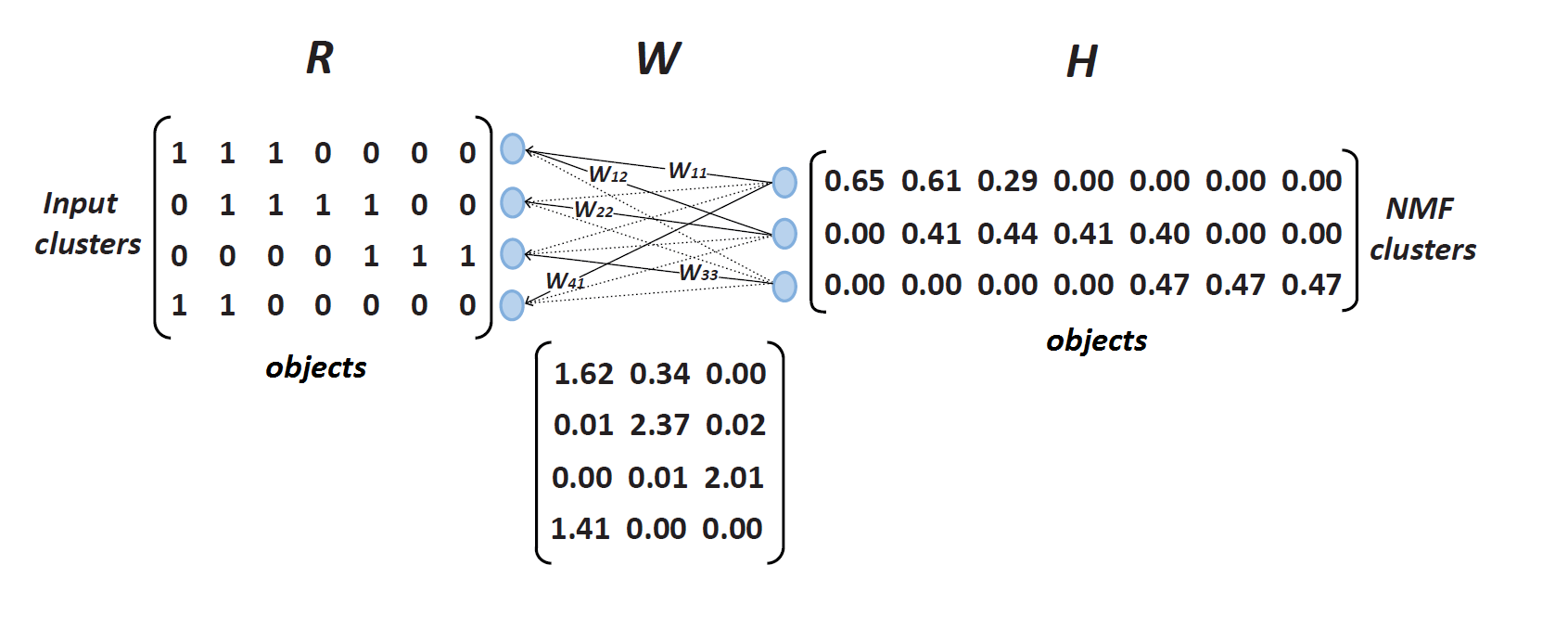
Još jedan inovativni algoritam koji je razvijen na Institutu BioSens je algoritam integrisane klasterizacije zasnovan na nenegativnoj faktorizaciji matrica. Kombinovanjem individualnih rezultata klasterovanja u ansambl, dokazi se akumuliraju u cilju poboljšanja rezultata klasterizacije.
Individualni rezultati klasteriziacije spojeni su u zajedničku matricu koja se zatim faktorizuje u matrice kodovanja i bazne vektore. Algoritam ima mogućnost da integriše klastere koji potiču iz različitih baza podataka, različitih nivoa predprocesiranja ili poseduju različite podskupove obeležja.
Ovaj algoritam se pokazao kao izuzetno koristan za funkcionalnu genomiku. Dati pristup, zanosvan na nenegativnoj faktorizaciji matrica poseduje mogućnost fuzije različitih izvora podataka i rezultuje klasterima gena sa povećanom funkcionalnošću i pokrivenošću gena.