Knowledge discovery
With the occurrence of non-parametric machine learning models and especially with the rising popularity of deep neural networks, most of classifiers and regressors used today are essentially black boxes. Their accuracy is often unmatchable by any conventional model, and although we know the principles and mathematics behind them, we cannot directly infer the complex relationships between input and output features. Having an accurate model has a huge practical value, but in order to have richer knowledge about the problem and push the boundaries of science, we need to delve deeper into the black box.
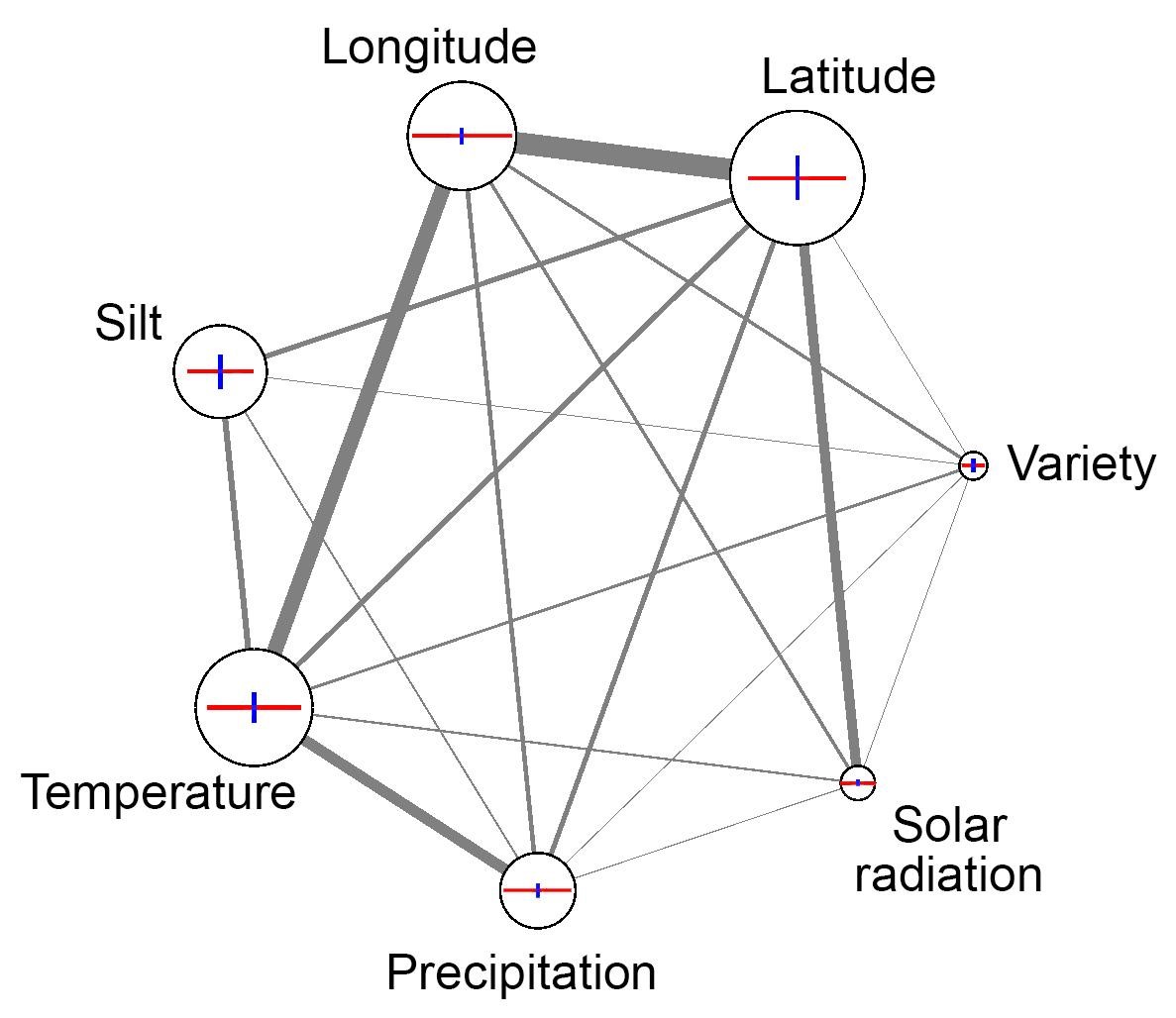
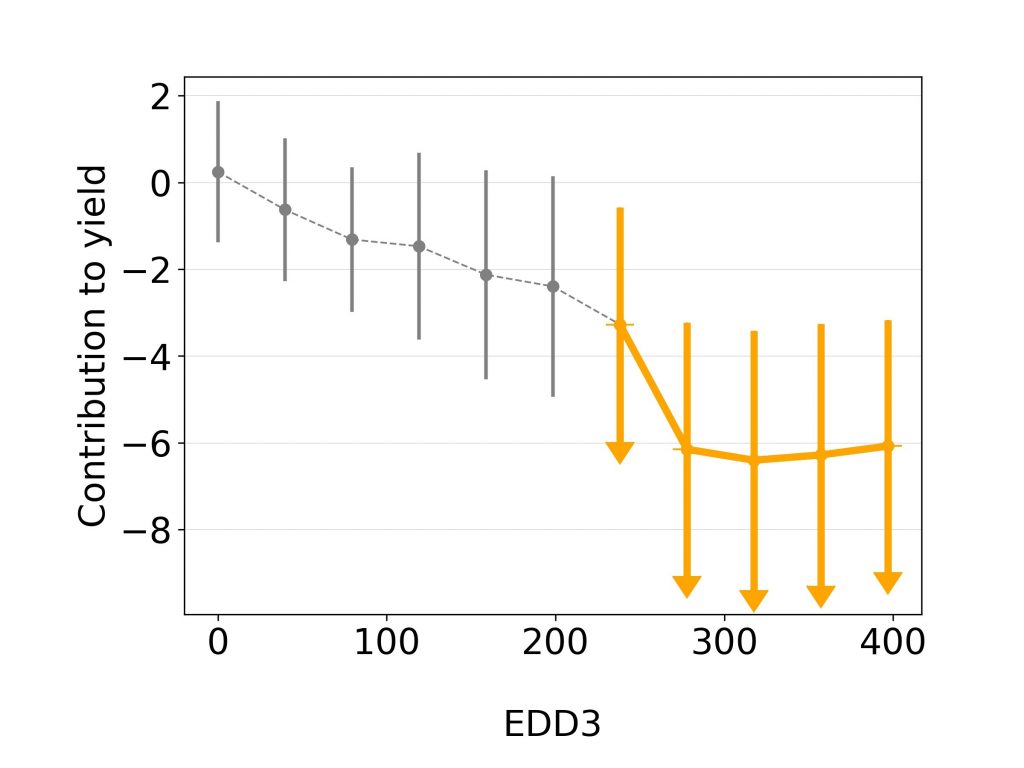
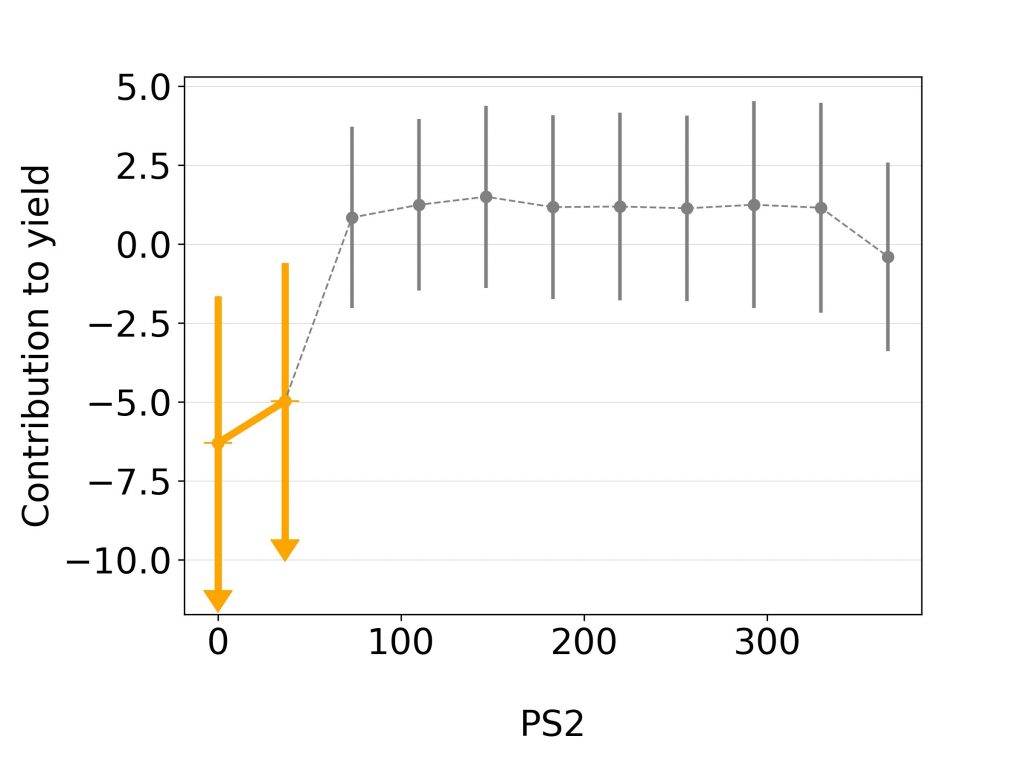
There are a few techniques we are relying on in knowledge discovery and all of them are based on indirect observations of the machine learning models. One of them is the random permutation test, which estimates the feature importance based on the decrease in model accuracy in case of random permutation of its values in the dataset. Morris’s and Sobol’s uncertainty and sensitivity analyses on the other hand are telling us more about the possible outputs of the system and the interaction between the input parameters. Model explanation analysis even goes a step further. For each feature used in predictive model, through sampling-based approximation it gives the estimate of feature’s positive or negative contribution to the output, which enables us to direct the domain researcher to where it’s the most effective. These and other methods allowed us to determine the influence of various soil and weather parameters on the yield and to characterise drought resistant maize hybrids or varieties of soya with stable yield.